

Uno de los mecanismos de exploración de datos más usados y efectivos son las representaciones gráficas de los elementos a partir de una base de datos.

Esta transformación de una base de datos a un formato visual nos permite identificar características y relaciones entre los elementos de los datos. Por defecto, R cuenta en su estructura base con múltiples funciones para la generación de gráficos, como nubes de puntos, líneas, barras, gráficos circulares, etc.
En el mundo de R hay muchas funciones que nos permiten realizar este tipo de gráficos, entre las más populares y completas, tenemos las funciones de gráfico propias de R, la cúal trataremos en este POST y funciones mucho más completas como ggplot2, función que veremos en una próxima oportunidad.
Recuerda que los pasos básicos son muy importantes conocerlos y no podemos dejar de verlos, ten paciencia que ya llegaremos a ver muchás más cosas que nos servirán en nuestros estudios biológicos.
Antes de correr, tuviste que aprender a caminar.
Ahora sí, vamos a por ello.
Gráficos básicos
La forma más básica de generar un gráfico de datos, es utilizando la función
Esta función tiene un comportamiento especial, pues dependiendo del tipo de dato que le demos como argumento, generará diferentes tipos de gráfica. Además, para cada tipo de gráfico, podremos ajustar diferentes parámetros que controlan su aspecto, dentro de esta misma función.

A continuación, veremos algunos ejemplos y cómo utilizarlos, para ello, usaremos la base de datos confiable
summary(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width
## Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100
## 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
## Median :5.800 Median :3.000 Median :4.350 Median :1.300
## Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199
## 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800
## Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500
## Species
## setosa :50
## versicolor:50
## virginica :50
##
##
## # clase de nuestras variables
lapply(iris, class)## $Sepal.Length
## [1] "numeric"
##
## $Sepal.Width
## [1] "numeric"
##
## $Petal.Length
## [1] "numeric"
##
## $Petal.Width
## [1] "numeric"
##
## $Species
## [1] "factor"Como podemos ver, tenemos 5 variables, 4 de ellas son del tipo
Diagrama de dispersión
Cuando estamos interesados en la interacción de dos variables cuantitativas, podemos hacer uso de este tipo de gráficas. Estos análisis permiten responder a preguntas como:
- ¿Existe alguna relación entre una variable
x con otra variabley ? - ¿Esta relación es negativa o positiva?
- ¿Mediante qué tipo de función se relacionan?, ¿Lineal o no lineal?
Los datos se representarán de izquierda a derecha en el eje X según el orden que ocupan en el vector, siendo su altura (posición en el eje Y) proporcional al valor del dato en sí. Así, podemos ingresar variables para poder inferir su posible comportamiento y relación. No te preocupes, ya explicaremos con más detalle.

Diagrama de dispersión de una variable
En el siguiente ejemplo vamos a representar graficamente la longitud de sépalo para las muestras de iris.
plot(iris$Sepal.Length)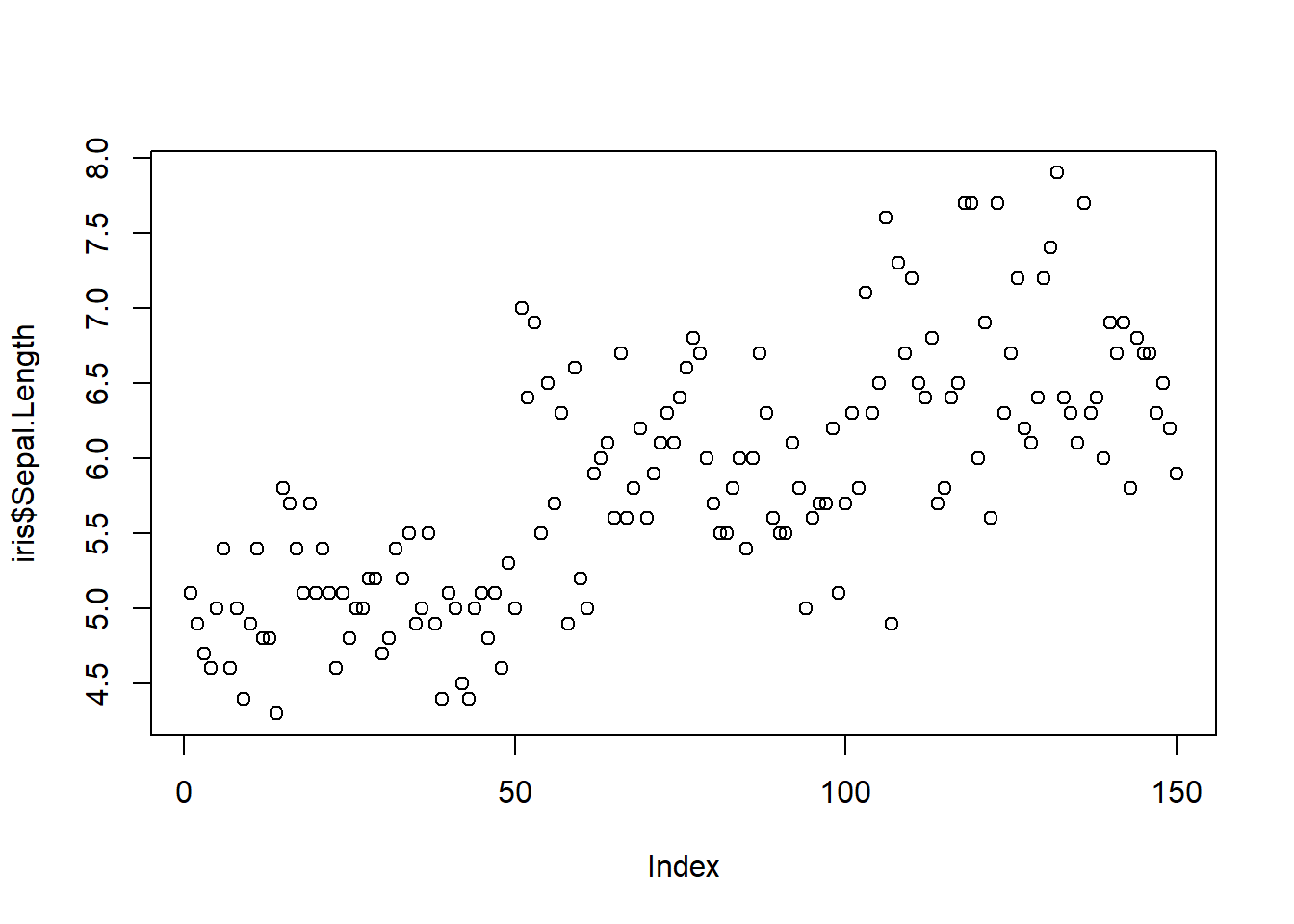
Como observamos, en el eje X aparecen las 150 observaciones, mientras que en el eje Y se indica la longitud de sépalo para cada observación. Pero si detallamos más a fondo de una simple gráfica podemos observar que más o menos los datos de las variables de la base, están ordenados. Los primeras muestran valores inferiores a los últimas, con un ascenso y cierto nivel de dispersión. Así, vamos observando pistas de lo que podríamos hacer con nuestros datos, paso a paso, ¡desenredamos esta maraña!

Diagrama de dispersión de dos variables
Este tipo de represetación se realiza para poder inferir una posible relación entre las variables, como vemos a continuación:
# Simplemente las separamos con una coma (,)
plot(iris$Sepal.Length, iris$Sepal.Width)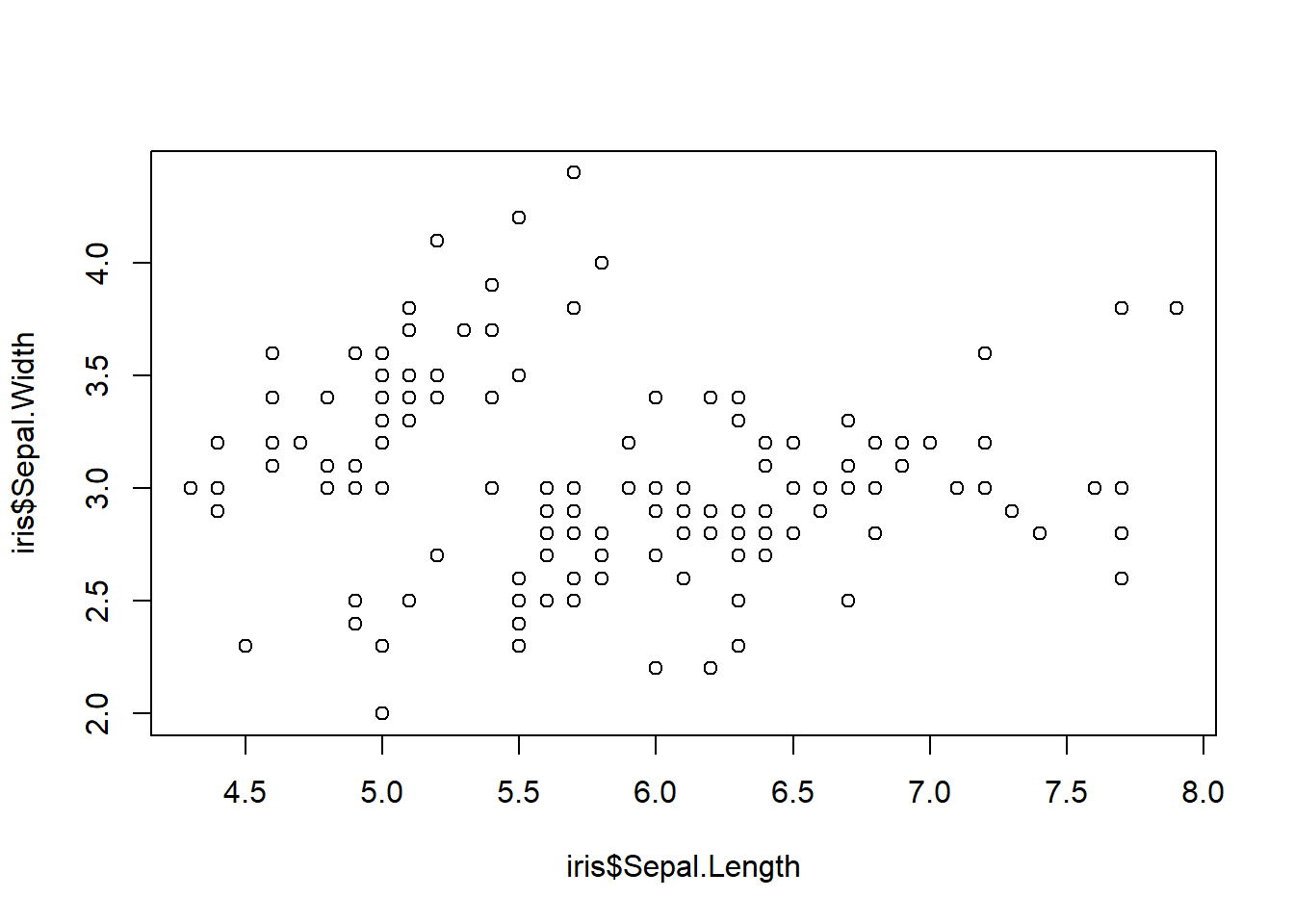
Pero como observamos, aquí no hay nada, nadita, nada. En este caso no podemos asegurar que hay una posible relación, ¿Y como sabemos esto? Es una apreación sencilla, no vas a observar que los puntos sigan un patrón (representada por una línea), no, en este caso los puntos están totalmente dispersos y por ello, podemos inferir que no hay una posible relación entre las dos variables.

Diagrama de dispersión de tres variables
Aunque en estas gráficas solamente contamos con dos ejes, y por tanto pueden representarse los valores correspondientes a dos variables, es posible aprovechar los atributos de los puntos: color, tipo de símbolo y tamaño, para mostrar variables adicionales.
En el siguiente ejercicio se usa el color de los puntos para representar la especie de cada observación, añadiendo el parámetro
plot(iris$Sepal.Length, iris$Sepal.Width,
col = iris$Species)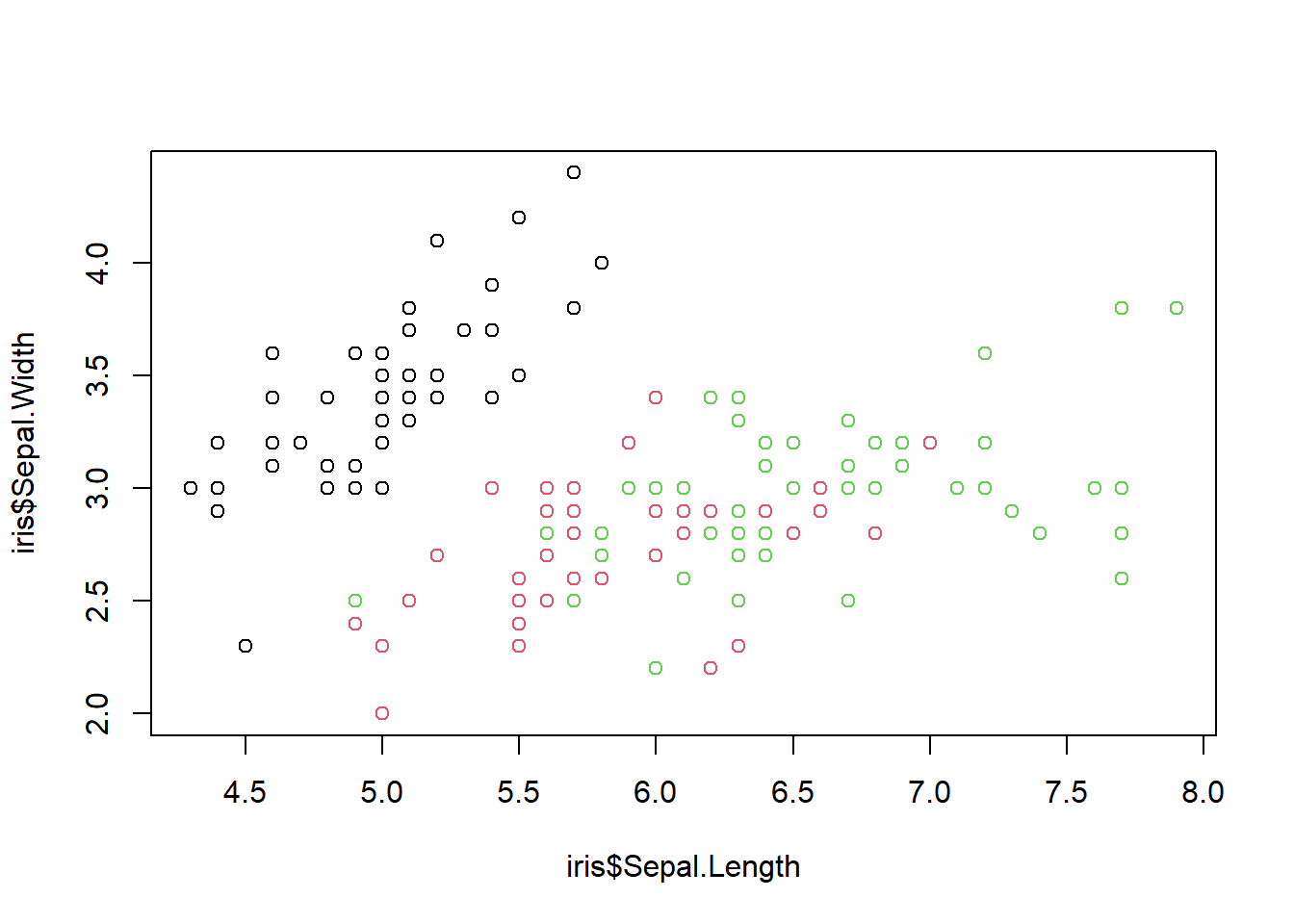
Como podemos observar nuestros datos van a tomar colores según la variable

Ahora demósle un poco de detalle a nuestra gráfica, para ello vamos a tener en cuenta algunas generalidades estéticas descritas a continuación:
- pch: valores numéricos (0 - 25) que especifican las formas de los puntos.
- cex: valores numéricos que indican el tamaño en puntos.
- col: nombre del color para los puntos.
# Ahora veamos las formas disponibles para pch:
library(ggpubr)
ggpubr::show_point_shapes()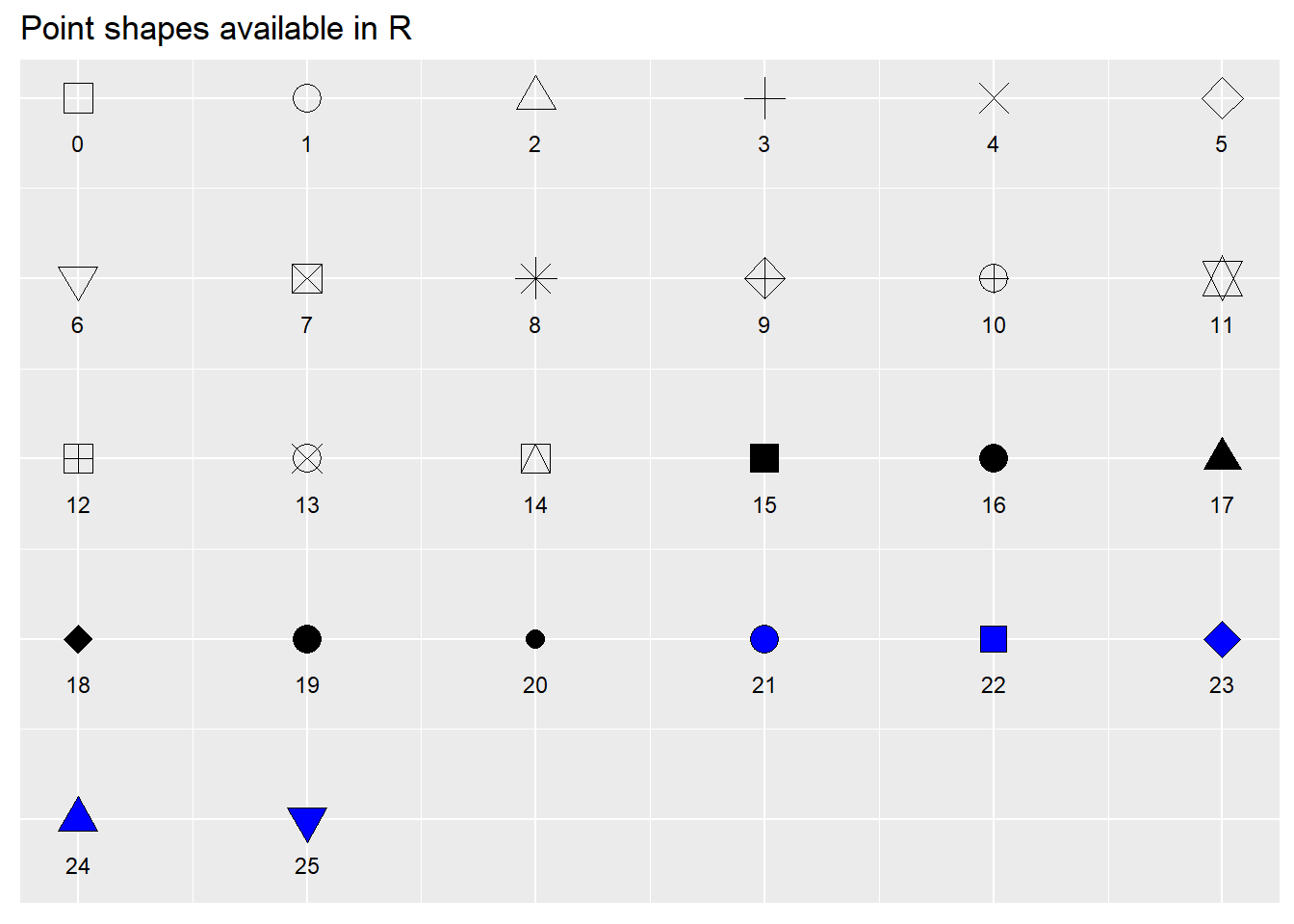
Además de otras que daremos a conocer en este código:
plot(iris$Petal.Length, iris$Petal.Width,
col = iris$Species,
pch = 19, ## Forma de los puntos
xlab = "Longitud del pétalo", ## Título del eje x
ylab = "Ancho del petalo") ## Título del eje y
# Titulos principales de la gráfica
title(main = "IRIS",
sub = "Exploración de los pétalos según especie",
col.main = "blue", col.sub = "grey") # Cambia su color
legend("bottomright", ## Posición de la leyenda
legend = levels(iris$Species), ## Datos para la leyenda
col = unique(iris$Species), ## Adjuntamos los colores
pch = 19, ## Forma de los puntos
bty = "n") ## Elimina la línea de la caja de la leyenda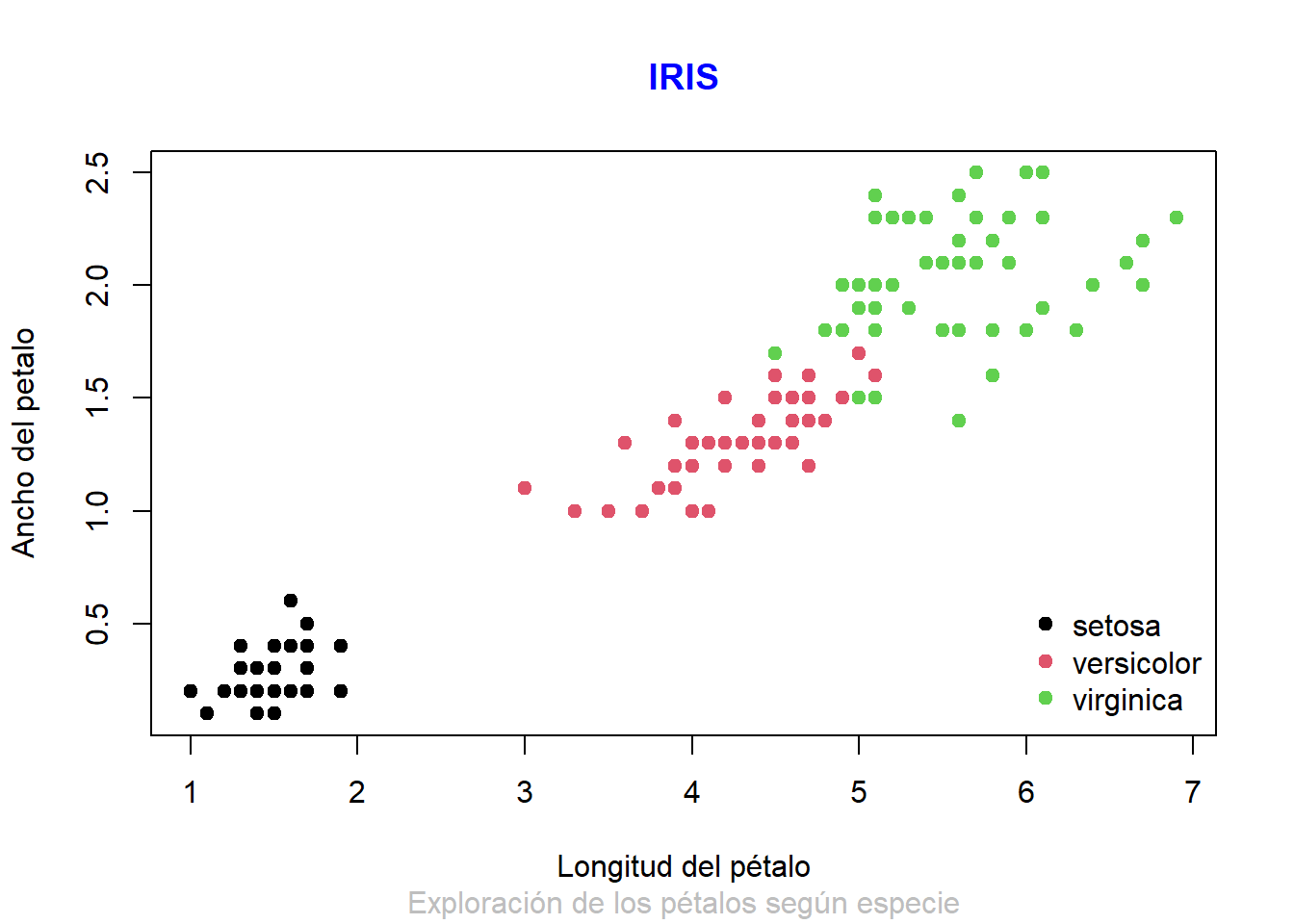
Así, podremos ir modificando algunas cosas para que nuestro gráfico sea mucho más presentable, en este paso ya es cuestión de estilos y gustos, practica, ensaya y modifica según tu preferencia, ¡Siéntete libre!

Gráfico de líneas
Los gráficos de líneas se utilizan para mostrar el valor cuantitativo en un intervalo o intervalo de tiempo continuo. Se usa con mayor frecuencia para mostrar tendencias y relaciones (cuando se agrupan con otras líneas). Los gráficos de línea también ayudan a dar un “panorama general” en un intervalo, para ver cómo se ha desarrollado durante ese período.
Para este ejercicio vamos a utilizar la siguiente base de datos, que es un estudio sobre escarabajos coprófagos. Las variables estudiadas son
La función par(mfrow = c(f, c)) que utilizaremos a continuación tiene como fin agrupar varios gráficos en un solo lienzo, para ello debemos especificar el número de filas y columnas que necesitaremos.
¡¡¡Atención, atención!!!
par(mfrow = c(1, 2)) # Necesitamos una fila y dos columnas
r<-read.csv(choose.files())
# Gráfica sin línea
plot(r$Dispersion, r$Longitud, main="Gráfica sin línea")
# Gráfica con línea
plot(r$Dispersion, r$Longitud,
type = "l", # Código para trazar la línea entre puntos
main="Gráfica con línea")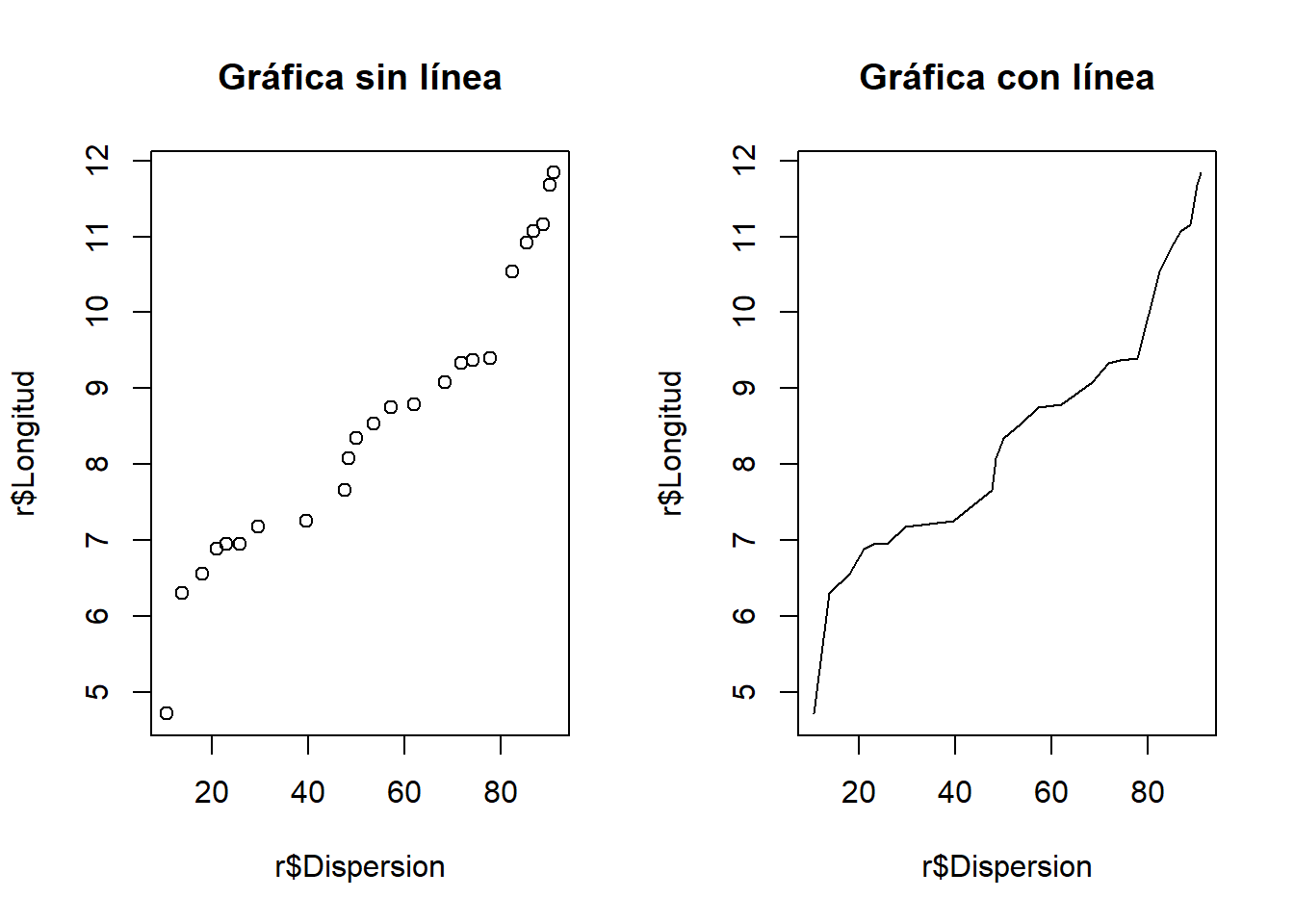
Como podemos observar para representar adecuadamente una gráfica de línea es indispensable agregar el argumento

Y lo trabajamos en el siguiente código:
plot(r$Dispersion, r$Longitud,
type = "l",
lwd = 4,
lty = 3,
col = "red",
main = "Estudio coprófagos")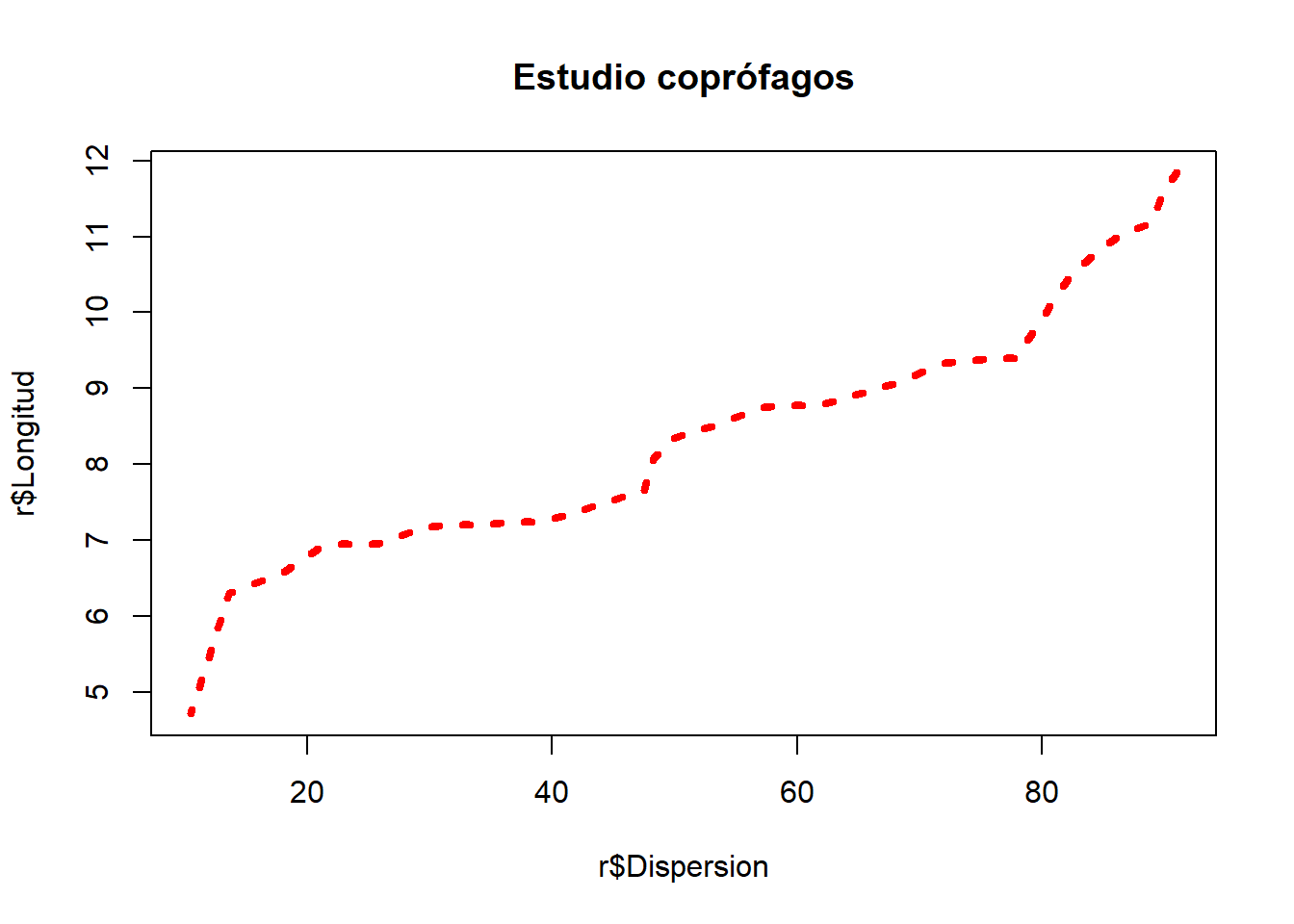
Y así vemos como podemos modificar el ancho y tipo de línea, un código sencillo y que te ayudará a darle más estilo a tus gráficas bases.
Gráfico de cajas
Este tipo de diagrama, conocido como gráfica de cajas y bigotes, nos permite apreciar de un vistazo el cómo se distribuyen los valores de una variable, si están más o menos concentrados o dispersos respecto a los cuartiles centrales, y si existen valores anómalos.
Una gráfica de este tipo dibuja un rectángulo cruzado por una línea recta horizontal. Esta linea recta representa la mediana, el segundo cuartil, su base representa el pimer cuartil y su parte superior el tercer cuartil. Al rango entre el primer y tercer cuartil se le conoce como intercuartílico (RIC).
Recuerda que el valor de x debe ser una variable del tipo factor
plot(iris$Species, iris$Petal.Length,
main = "Longitud de pétalos de 3 especies del género Iris",
xlab = "Especies",
ylab = "Longitud (cm)",
col = c("orange", "yellow", "green"),
font = 3)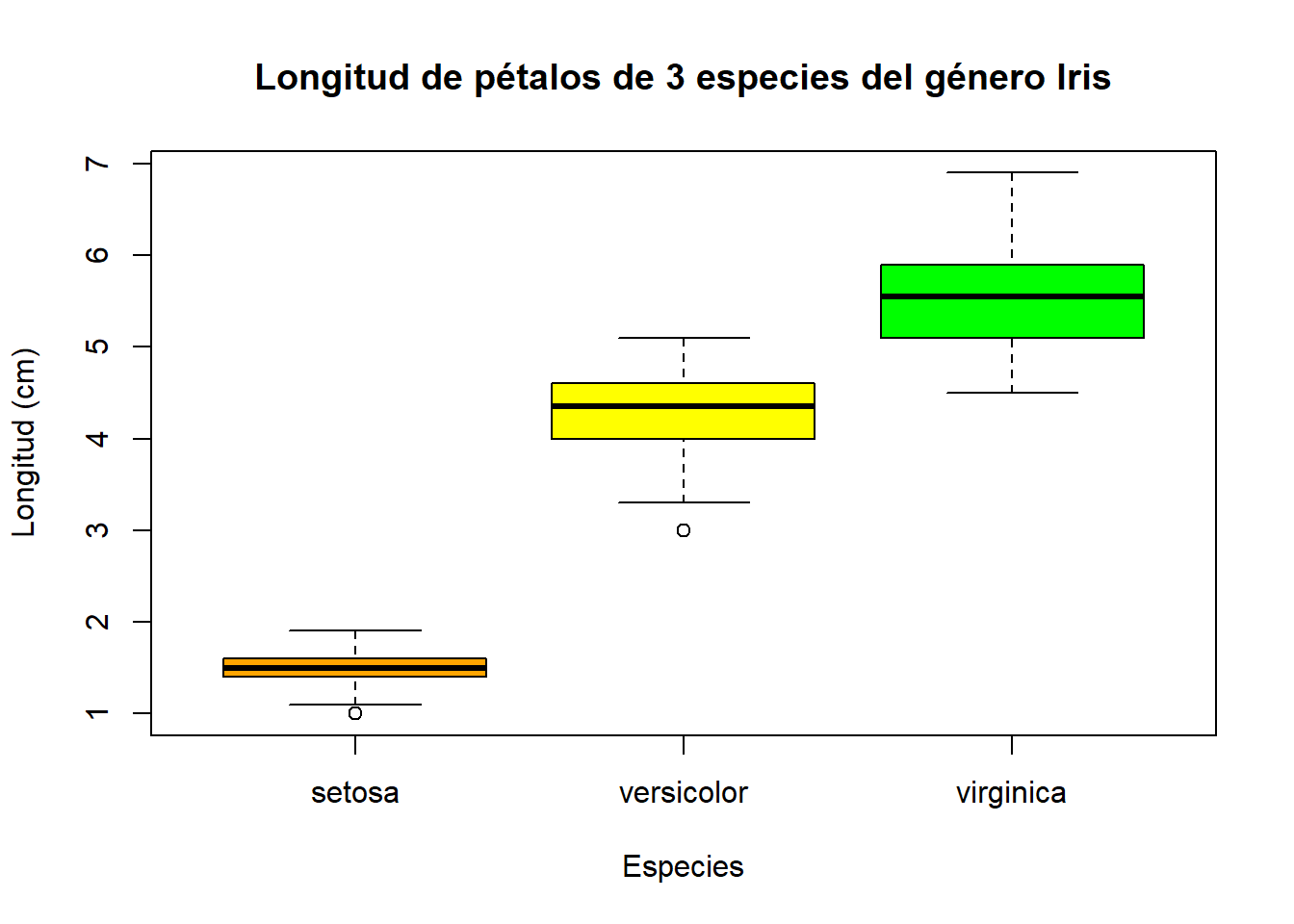
De esta manera, podemos observar que la especie I. setosa posee pétalos y sépalos de menor tamaño con respecto a las otras especies estudiadas, donde la especie I. virginica al parecer posee los sépalos y pétalos de mayor tamaño.

Gráfico de barras
Este es quizás el tipo de gráfico mejor conocido por todos. Una gráfica de este tipo nos muestra la frecuencia con la que se han observado los datos de variables cualitativas o cuantitativas discretas con un rango limitado de valores (número de cilindros de un vehículo, número de hijos de una persona, etc.), con una barra para cada categoría de esta variable.
La función
plot(x = chickwts$feed,
col=c('red','black','green','blue', 'orange', 'grey'),
xlab="Suplementos alimenticios",
ylab="Total de experimentos",
main="Suplementos alimenticios en pollos")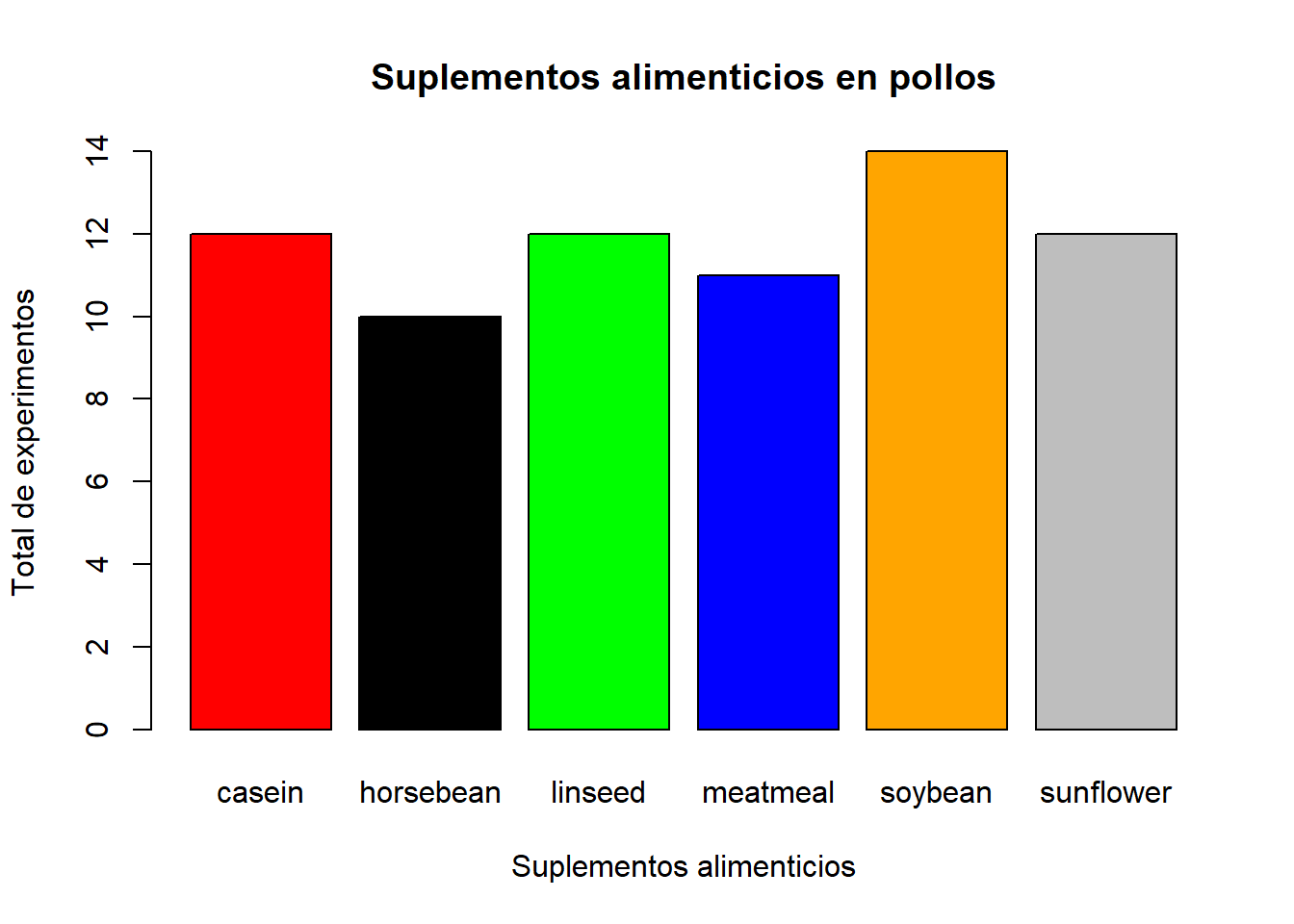
Por supuesto, este tipo de gráficos también permite personalizarlo para cambiar su aspecto visual. Por ejemplo, podemos mostrar las barras en sentido horizontal.
plot(x = chickwts$feed,
border = 'red', ## Color borde de las barras
col = 'green', ## Color barras
xlab = "Frecuencia",
main = "Suplementos alimenticios en pollos",
horiz = 1, ## Código para las barras horizontales
las = 1, ## Orientación de las etiquetas del eje
## siempre horizontal (1), siempre perpendicular al eje (2) y siempre vertical (3)
space = 0, ## Espacio entre barras
width = c(3,1,3,2,4,3)) ## Ancho de las barras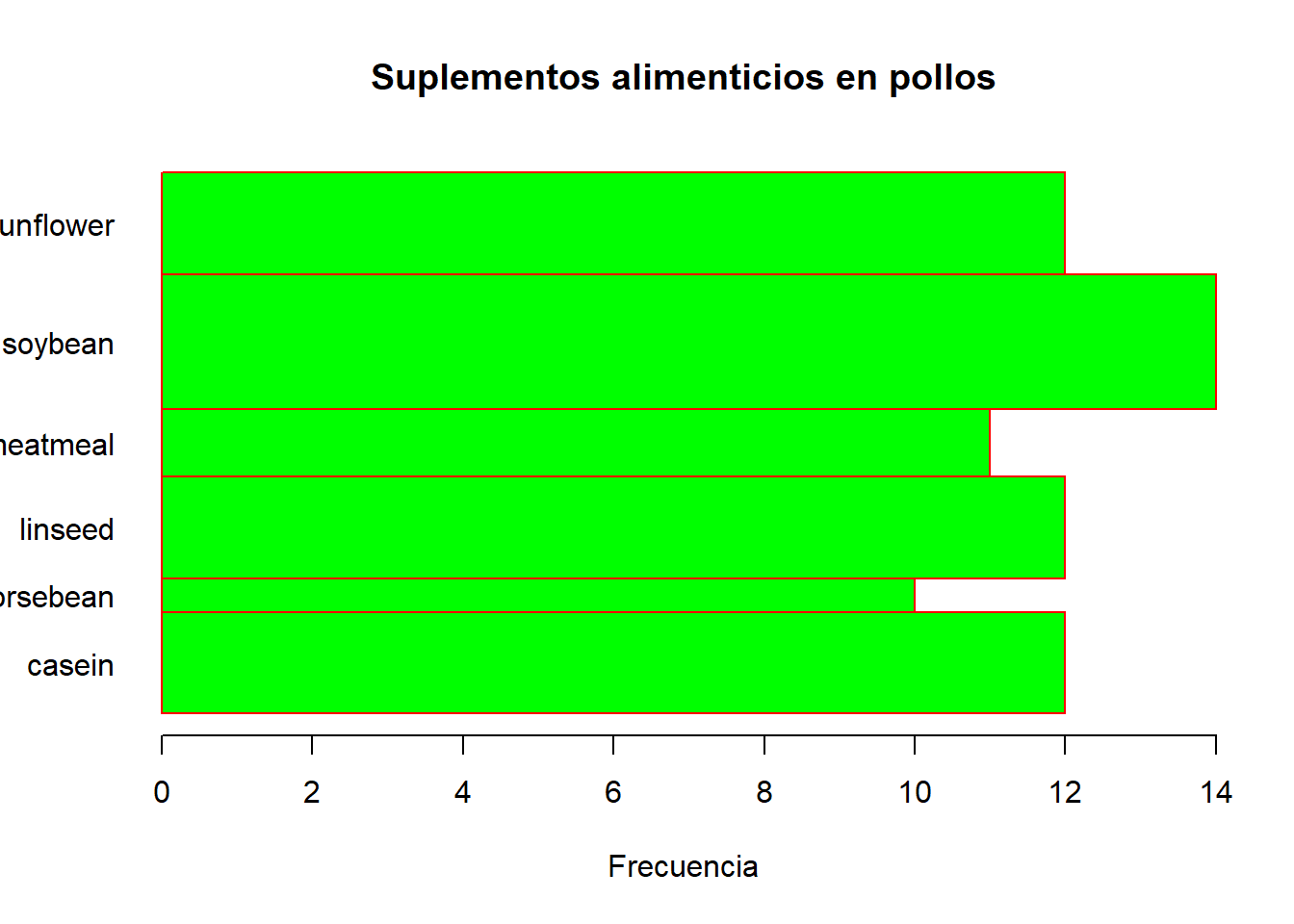
Y así obtenemos nuestro gráfico y quedó según nuestras especificaciones, con lo cuál ya podemos dar un análisis previo de sus datos. Por ejemplo, acá podemos observar que la cantidad del suplemento alimenticio

Gráfico Histograma
Un histograma visualiza la distribución de los datos a lo largo de un intervalo continuo o un período de tiempo determinado. Cada barra en un histograma representa la frecuencia tabulada en cada intervalo/barra. El área total del histograma es igual al número de datos.
Los histogramas ayudan a dar una estimación de dónde se concentran los valores, cuáles son los extremos y si hay vacíos o valores inusuales. También son útiles para dar una visión aproximada de la distribución de probabilidad.
Para crear un histograma, vamos a utilizar los siguientes datos, que representan las distancias (en yardas) que recorre un ave cada hora en un estudio de monitoreo de la especie.
distancia <- c(241.1, 284.4, 220.2, 272.4, 271.1, 268.3,
291.6, 241.6, 286.1, 285.9, 259.6, 299.6,
253.1, 239.6, 277.8, 263.8, 267.2, 272.6,
283.4, 234.5, 260.4, 264.2, 295.1, 276.4,
263.1, 251.4, 264.0, 269.2, 281.0, 283.2)Este tipo de gráfico es de los pocos que no utilizamos con la función

hist(distancia, main = "Histograma de frecuencias",
ylab = "Frecuencia",
xlab = "Yardas de vuelo",
col = "cyan3")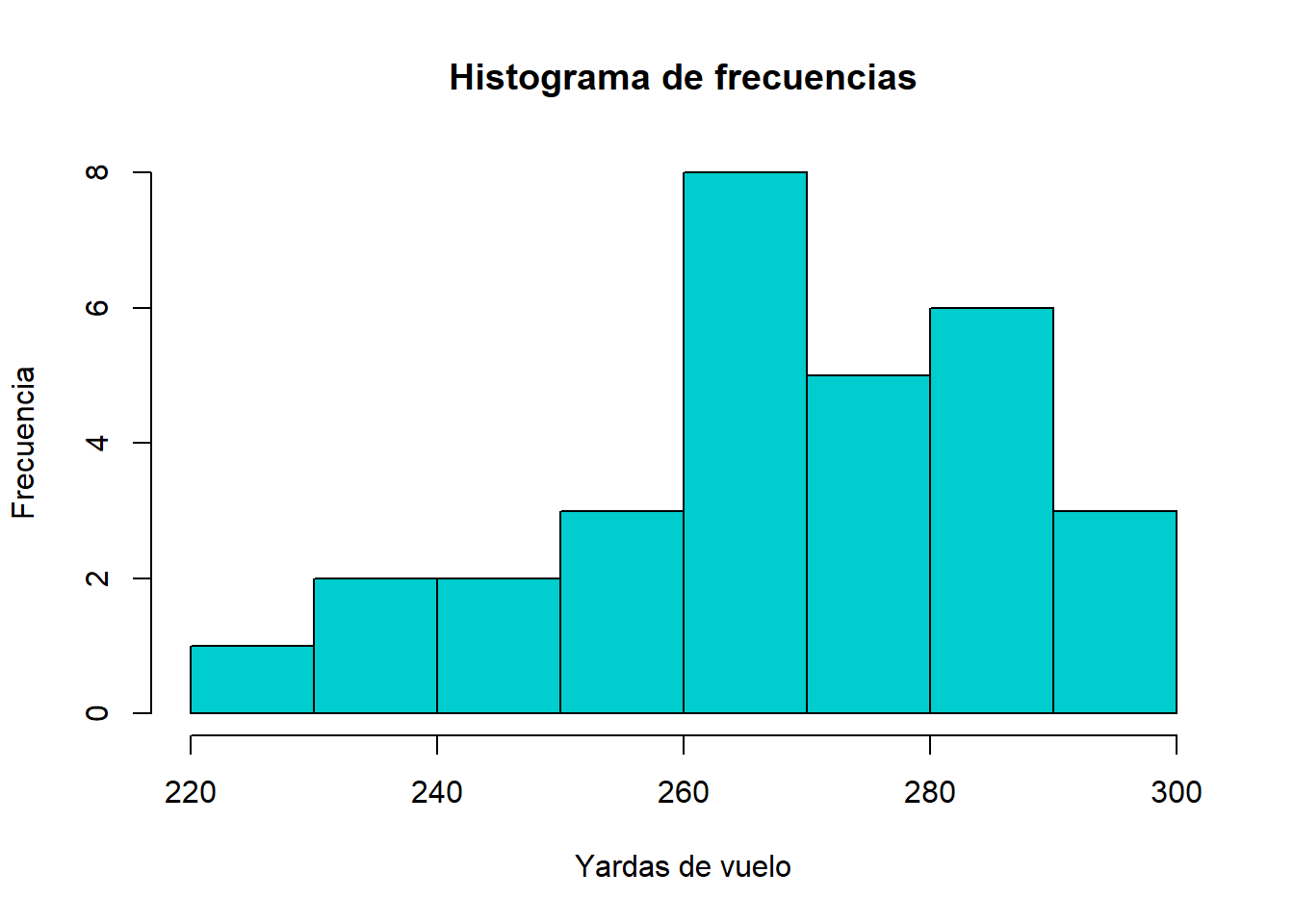
Así podemos observar que en general el total de yardas más frecuente en el estudio fue entre 260 y 270 yardas, caso contrario, los valores menos frecuentes se presentan entre 220 y 230 yardas.
Cabe aclarar que los histogramas son muy útiles para representar la distribución de los datos si el número de barras o clases se selecciona correctamente. Sin embargo, la selección del número de barras (o el ancho de las barras) puede ser complicada, debido a dos factores:
- Pocas clases agruparán demasiado las observaciones.
- Con demasiadas clases habrá pocas observaciones en cada una de ellas aumentando la variabilidad del gráfico obtenido.
Hay varias reglas para determinar el número de barras; en R, el método de Sturges se usa por defecto. Si quieres cambiar el número de barras, pasa al argumento
La fórmula del método de Sturges se muestra a continuación
No barras = 1 + 3.3log(n)
n = Datos totalespar(mfrow = c(1, 3)) # Necesitamos una fila y tres columnas
hist(distancia, breaks = 2, main = "Pocas clases", ylab = "Frecuencia")
hist(distancia, breaks = 50, main = "Demasiadas clases", ylab = "Frecuencia")
hist(distancia, main = "Método de Sturges", ylab = "Frecuencia")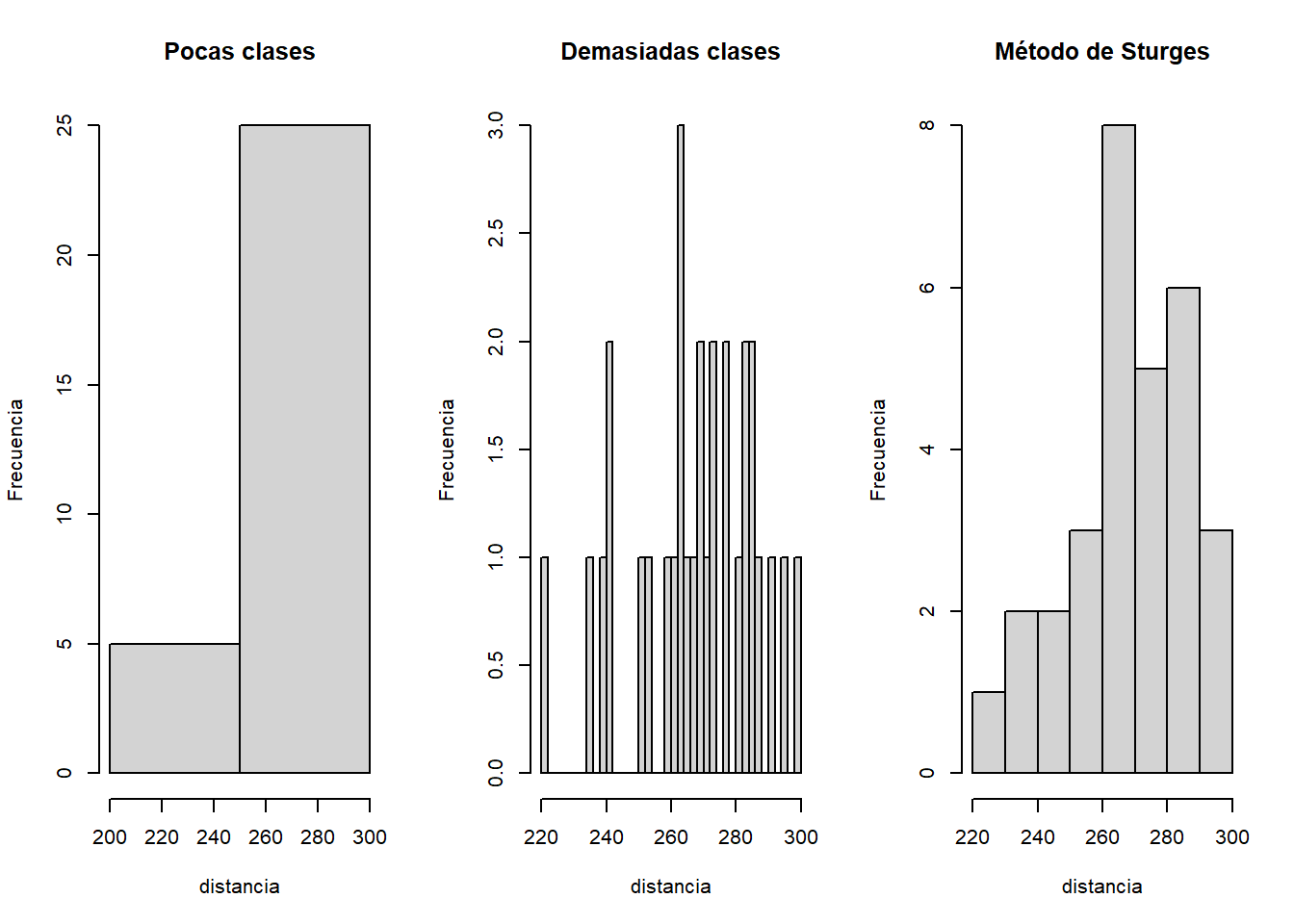
Como puedes observar, entre estos gráficos difiere mucho su análisis, por tanto, te recomendamos dejarlo por defecto, sin embargo, dependiendo de tu pregunta de investigación o tus objetivos a cumplir, puedes modificar su estructura.
¿Cansado? ¿Mucha información? Take it easy, no te apures, no querrás terminar más loco de lo que ya estás. Es de tiempo, ve despacio.

Gráfico de densidad
Un gráfico de densidad visualiza la distribución de datos en un intervalo o período de tiempo continuo. Este gráfico es una variación de un Histograma que usa el suavizado de cerner para trazar valores, permitiendo distribuciones más suaves al suavizar el ruido. Los picos de un gráfico de densidad ayudan a mostrar dónde los valores se concentran en el intervalo.
plot(density(distancia),
main="Gráfico de Densidad")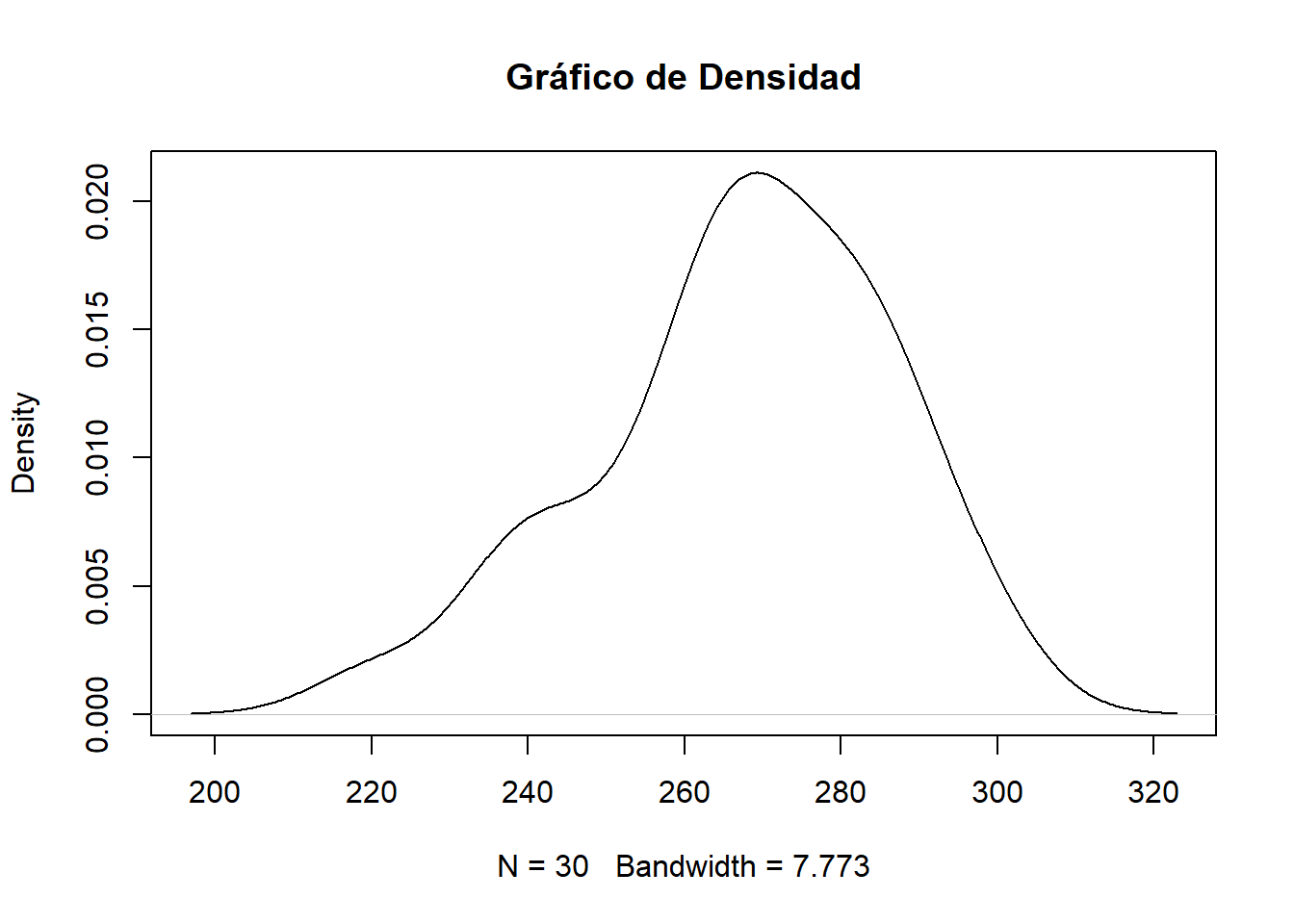
Igualmente podemos representar la densidad de los datos a partir de barras, para ello utilizaremos nuevamente la función
hist(distancia, prob = TRUE, main = "Histograma de densidad",
ylab = "Densidad")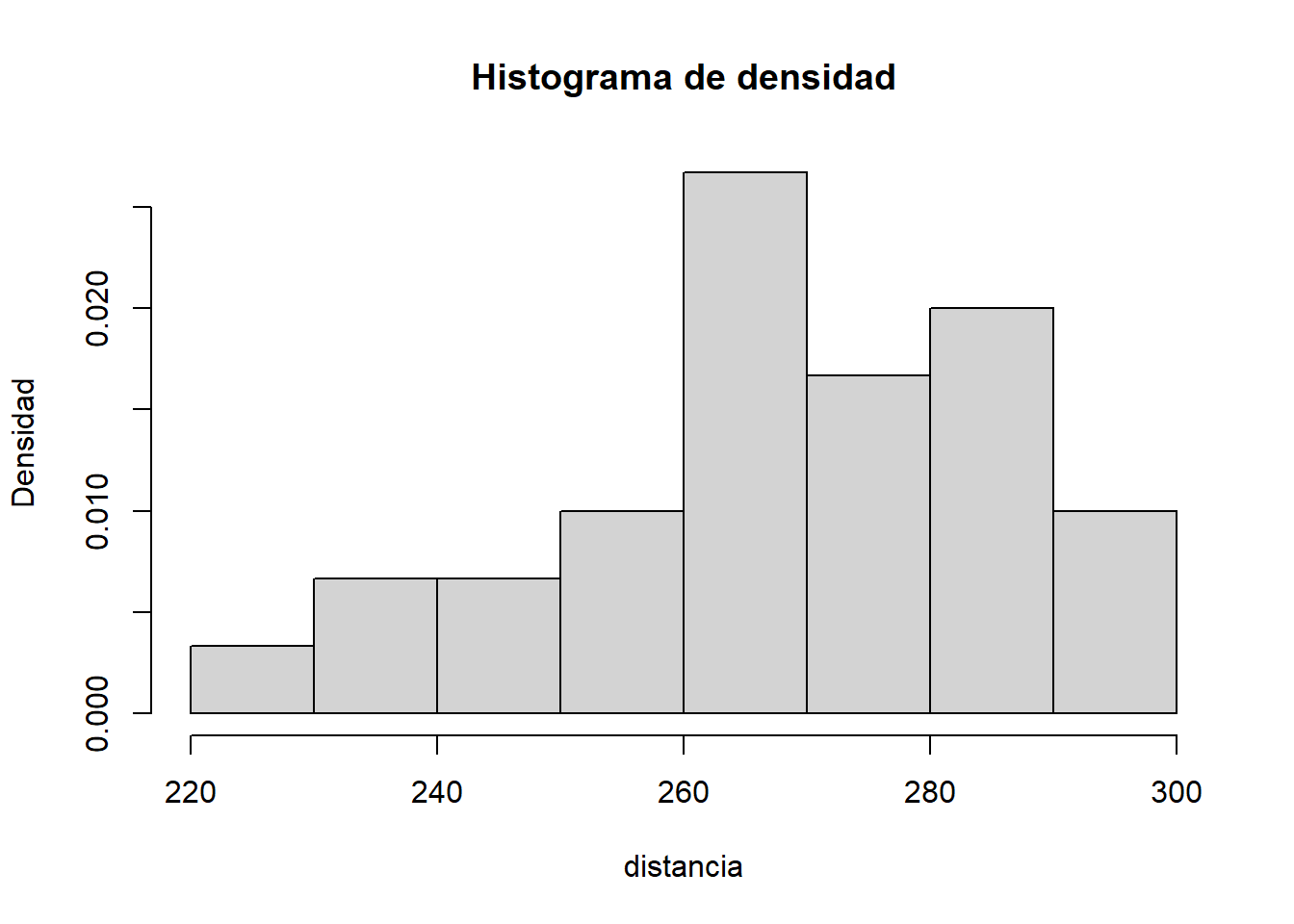
Como podemos observar nuestro eje “Y” ha cambiado su escala, ya que se trata de una representación de densidad más no de frecuencia.

Pa’ finalizar
Hoy hemos aprendido un paso importante en el análisis de nuestros datos a partir de una manera visual. Tal vez no te sientas tan cómodo leyendo números y no sea tan fácil ver tendencias entre los números. Quizá tu inteligencia sea más artísitica, y los gráficos te caerán de perlas.
Podrás ver posibles tendencias, formas, datos extraños, etc. Sólo es cuestión de concentrarte un poco y mirar más allá de lo que ven tus ojos, así como cuando miras al amor de tu vida…

Y bueno… llegó la hora de la despedida, no te preocupes, de pronto coincidamos de nuevo en un nuevo POST. Mientras tanto, práctica, lee y recuerda que: ¡Puedes hacer estas cosas y muchas más! Sólo es cuestión de creer en tí mismo, ¡Ánimo!
Hasta prontooo…

Bibliografía
Revisión
Recuerda que todos nuestros códigos están almacenados en GitHub
